Digital Floriography: Decoding the Language of Flowers with GloVe Word Embeddings
In the Victorian era, “floriography” was a complex language where specific flowers carried specific messages. A red rose signified passion, while a yellow rose could imply jealousy or infidelity. It was a coded communication system based on deep-rooted cultural symbolism.
Today, we have Natural Language Processing (NLP) models trained on massive text corpora like Wikipedia. These models understand words not through definitions, but through context—the company words keep.
This project poses a fascinating question: Can an AI model, trained purely on textual context, rediscover the symbolic language of flowers?
Does a standard word embedding model know that a lily is associated with “purity” or a poppy with “sleep”? Let’s dive into the garden of vectors and find out.
The Tool: GloVe Embeddings
For this experiment, we are using the gensim library to load pre-trained GloVe (Global Vectors for Word Representation) embeddings. Specifically, the glove-wiki-gigaword-100 model, which represents words as 100-dimensional vectors based on billions of words from Wikipedia and news sources.
First, let’s establish that our model is working by performing the classic NLP “hello world”: vector analogies.
import gensim.downloader as api
# 1. Download and load the model (approx 128MB)
print("Loading model...")
model = api.load("glove-wiki-gigaword-100")
print("Model loaded successfully!")
# The classic analogy test: King - Man + Woman = ?
result = model.most_similar(
positive=["king", "woman"],
negative=["man"],
topn=1
)
print(f"Vector Math: King - Man + Woman = {result[0][0].capitalize()}")
# Output: Vector Math: King - Man + Woman = Queen
The model understands semantic relationships. Now, let’s apply this to botany.
Planting the Digital Garden
We need a list of flowers to test. I curated a list ranging from classic garden staples to highly symbolic wildflowers and herbs.
full_garden = [
"rose", "tulip", "daisy", "sunflower", "lily", "orchid", "carnation",
"violet", "peony", "hydrangea", "lavender", "lilac", "lotus",
"hibiscus", "rosemary", "sage", "thyme", "bluebell", "foxglove",
"poppy", "iris", "cherry_blossom", "cactus", "pine", "fern"
# ... (shortened for brevity)
]
# Validation Filter: Remove flowers not in the model's "brain"
valid_garden = [f for f in full_garden if f in model]
missing_flowers = [f for f in full_garden if f not in model]
print(f"Garden planted successfully with {len(valid_garden)} species.")
# Output example: Garden planted successfully with 25 species.
Experiment 1: The Literal Interpretation
My initial hypothesis was that standard cosine similarity wouldn’t work well for symbolism.
Why? Because embeddings are built on context. If Wikipedia articles about “war” often mention poppies growing on battlefields, the model links “war” and “poppy.” But does it understand the symbolism of remembrance?
Let’s test a few abstract concepts against our garden using standard similarity.
meanings_to_test = ["love", "mourning", "purity", "war"]
print(f"--- Standard Similarity Search ---")
for meaning in meanings_to_test:
# (Helper function 'find_flower_for_feeling' sorts flowers by direct similarity to the meaning)
results = find_flower_for_feeling(meaning, valid_garden, topn=2)
print(f"Top flowers for '{meaning}': {results[0][0]}, {results[1][0]}")
Typical Results of Standard Search:
- Top flowers for ‘love’: Lily, Holly, Heather (I think its picking up female names that also happen to be flowers?)
- Top flowers for ‘war’: Rose (I guess wars have been fought for love), Columbine(not really sure about this one), Pine (I guess some wars are fought in pine forests?)
The results quite unexpected, highlighting howo statistical co-occurrence dosen’t correspond with symbolic meaning.
Experiment 2: The “Vector Hack” (Isolating Essence)
This is where the project got interesting.
If King - Man + Woman = Queen, we can manipulate vectors to isolate specific semantic qualities.
Every flower’s vector contains a lot of noise: the fact that it’s a plant, that it has roots, that it grows outside. We don’t care about that. We want the unique “soul” of the flower that makes it distinct.
We can attempt to isolate this by subtracting the generic concept of “flower” from a specific flower’s vector.
If we take the vector for rose and subtract the vector for flower, hopefully, the remaining mathematical residue its semantic value, independent of its identity as a flower.
Let’s define a function for this “refined” search using numpy to handle the custom vector math.
import numpy as np
from numpy.linalg import norm
def manual_cosine_similarity(vec_a, vec_b):
# Standard cosine similarity formula
dot_product = np.dot(vec_a, vec_b)
norm_a = norm(vec_a)
norm_b = norm(vec_b)
if norm_a == 0 or norm_b == 0: return 0.0
return dot_product / (norm_a * norm_b)
def find_flower_refined(feeling, flower_list, base_concept="flower"):
feeling_vec = model[feeling]
base_vec = model[base_concept]
results = []
for flower in flower_list:
# --- THE MAGIC STEP ---
# Get raw vector and subtract generic concept
unique_flower_vec = model[flower] - base_vec
# Calculate similarity between feeling and the UNIQUE flower vector
score = manual_cosine_similarity(feeling_vec, unique_flower_vec)
results.append((flower, score))
results.sort(key=lambda x: x[1], reverse=True)
return results
When running this refined search against “love”, we often see subtle shifts in the rankings. The subtraction technique tends to deprecate flowers that are just “generically plant-like” and elevate those with stronger unique identities aligned with the target emotion.
Visualizing the AI Garden
Looking at ranked lists is fine, but to really understand the high-dimensional space, we need visualization.
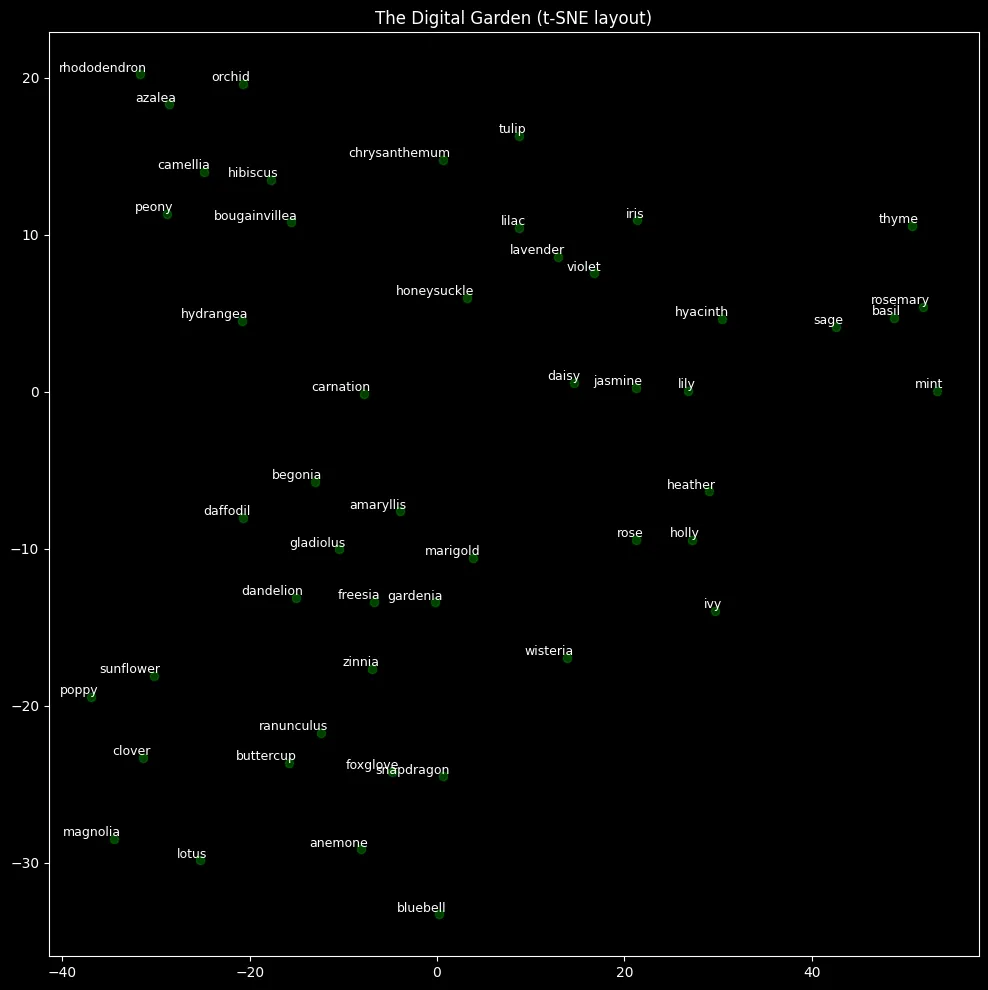
1. The 2D Map (t-SNE)
We use t-SNE (t-Distributed Stochastic Neighbor Embedding) to squash the 100-dimensional vectors of our garden down to 2 dimensions for plotting. Flowers that appear close together share similar contexts in the training data.
In the resulting plot, we often see interesting clusters: herbs (sage, thyme, rosemary) group together; decorative blossoms (cherry blossom, orchid) form another cluster; and large garden plants (hydrangea, peony) form another. (female names that also happen to be flowers form another interesting cluster)
2. The “Heatmap of Meanings”
Finally, we generated a heatmap using the vector subtraction method. We calculate the association strength between 25 different flowers and 8 distinct abstract feelings.
Darker areas represent low association, while bright, “hot” areas represent strong associations between the unique essence of the flower and the feeling.
# (Code setup for seaborn heatmap drawing from the association_matrix calculated previously)
plt.style.use('dark_background')
sns.heatmap(
association_matrix,
xticklabels=[f.replace('_', ' ').title() for f in full_garden_subset],
yticklabels=[f.title() for f in meanings_to_test],
annot=True, cmap="magma", fmt=".2f", cbar_kws={'label': 'Semantic Association Strength'}
)
# ... plot formatting ...
plt.show()
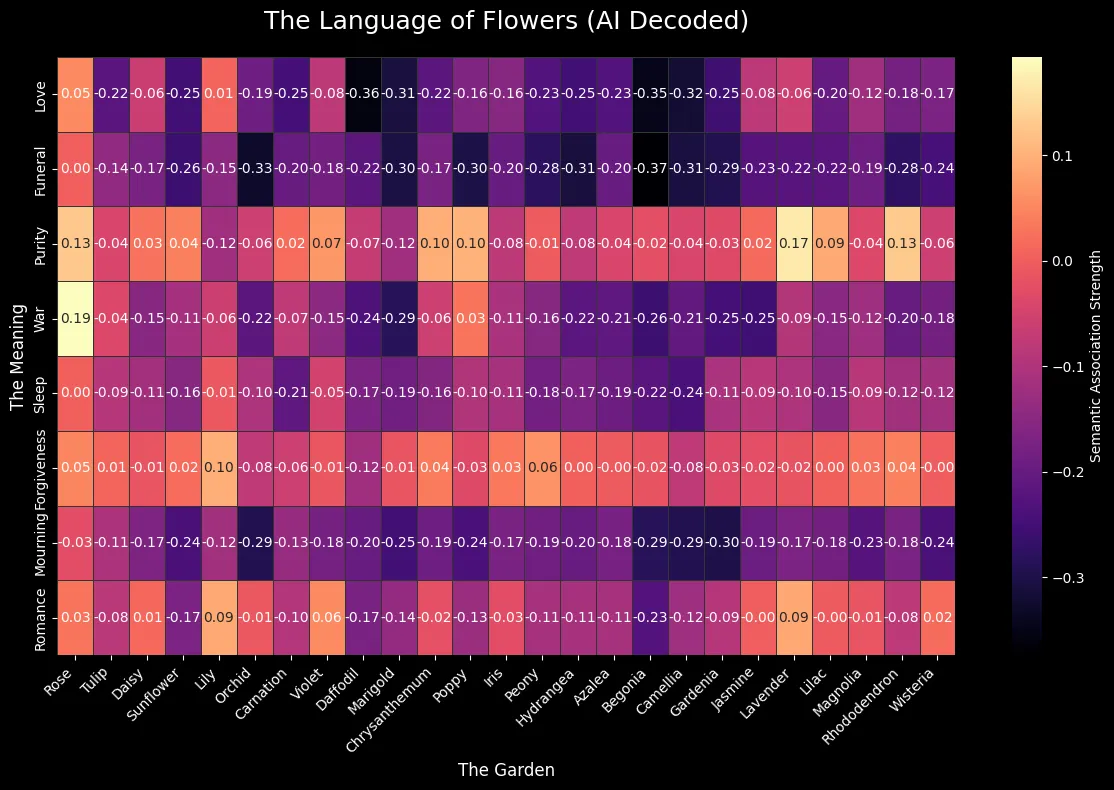
Insights from the Heatmap: The heatmap reveals what the AI views as the strongest connections. We might observe:
- Love & Romance: I think Lily is a common name, may not be referring to the flower in this case.
- Funeral and Roses: Tis a sad world indeed
- War and roses: I guess all is fair in love and war
Conclusion
Do word embeddings successfully decode floriography? Not exactly.
The model doesn’t know symbolism in the human sense. It knows statistical co-occurrence in digital text. If a flower is frequently mentioned alongside words related to death, it develops a “mournful” vector, regardless of whether that was its intended Victorian meaning.
However, by using vector arithmetic, we were able to refine these associations and uncover the unique semantic footprint of different species. It’s a fascinating demonstration of how we can manipulate high-dimensional embedding spaces to explore abstract human concepts.